Pharma Forensics: How to Decode Formulation Patents and Expose a Competitor’s Lifecycle Strategy
Every patent a pharmaceutical company files is a sworn, detailed confession. It tells you what the company’s chemists have been […]
Every patent a pharmaceutical company files is a sworn, detailed confession. It tells you what the company’s chemists have been […]
Who this is for: Formulation scientists, regulatory affairs directors, IP counsel, and business development executives at generic and specialty pharmaceutical
Designing Around the Moat: A Generic Developer’s Guide to Secondary Formulation Patents Read Post »
Every year, somewhere between $20 billion and $80 billion in branded drug revenue falls off a cliff. Not metaphorically. Literally:
In the summer of 2022, a mid-sized generic manufacturer’s legal team spent six weeks and roughly $400,000 running keyword searches
Beyond Keywords: How AI and NLP Find Hidden Prior Art in Chemical and Biologic Patents Read Post »
Every formulation patent is a public confession. The inventor must disclose, in precise technical detail, exactly what makes the product
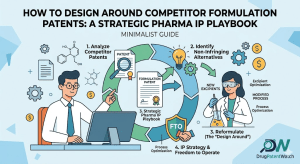
How to Design Around Competitor Formulation Patents: A Strategic Pharma IP Playbook Read Post »
Biologic drugs account for roughly 2% of all U.S. prescriptions. They generate 37% of total net drug spending [1]. That

When Mylan filed its first abbreviated new drug application (ANDA) for a controlled-release oxycodone formulation, AstraZeneca’s legal team didn’t panic
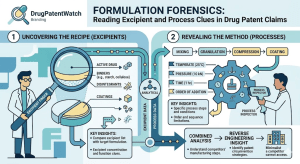
Formulation Forensics: How to Read Excipient and Process Clues in Drug Patent Claims Read Post »
Biologic drugs represent 2% of all U.S. prescriptions but consume 37% of net drug spending. [1] That arithmetic explains everything
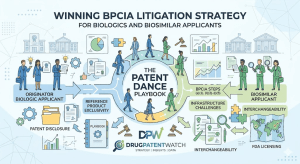
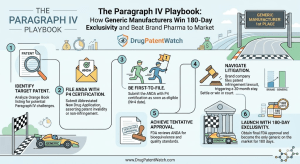
Every year, hundreds of millions of dollars shift hands based on a single question: who filed first? The Paragraph IV
Sign in or create a free account to read this DrugPatentWatch article
